Automating dialogs by learning cognitive actions on a shared workspace
Summary
How can we leverage machine learning to help people think? When people try to make progress on vague problems that require reasoning, natural language is usually their most powerful tool. They can take notes, read articles and books, and exchange ideas in conversations. If we want to build tools that support people’s thinking, one promising avenue is to look into machine learning systems that interact with people using natural language.
If we want our systems to be accessible by a wide range of people without special training, natural language dialog is a particularly appealing interface, since it’s such a natural means for communicating ideas.
Existing work on dialog automation tries to directly predict the next utterance given the conversation so far. This is challenging, especially for conversations that require substantial reasoning (“analytic dialogs”). It also makes it difficult for humans to provide help that is more fine-grained than simply providing the next response.
We can instead slice the problem of predicting the next response into a sequence of smaller prediction problems. At each point, we predict a next “cognitive action” on a human-readable workspace that contains notes on the dialog so far, ongoing considerations, and things to discuss and investigate in the future. These actions can be learned based on data collected from humans, who can now assist precisely where our algorithms aren’t yet capable enough.
Dialog automation using machine learning
There is a wide variety of approaches to dialog automation, including:
- Pattern-action rules (e.g., Eliza)
- Information retrieval from large datasets (e.g., Cleverbot)
- Stochastic state machines with atomic or factored state representations, sometimes trained using reinforcement learning (MDPs, POMDPs; e.g., Young 2013)
- Deep neural nets (e.g., Vinyals 2015, Serban 2015)
- Deep reinforcement learning (e.g., Li 2016, Kandasamy 2017)
Essentially all systems maintain some sort of state over the course of a conversation and choose the next response based on the current state:
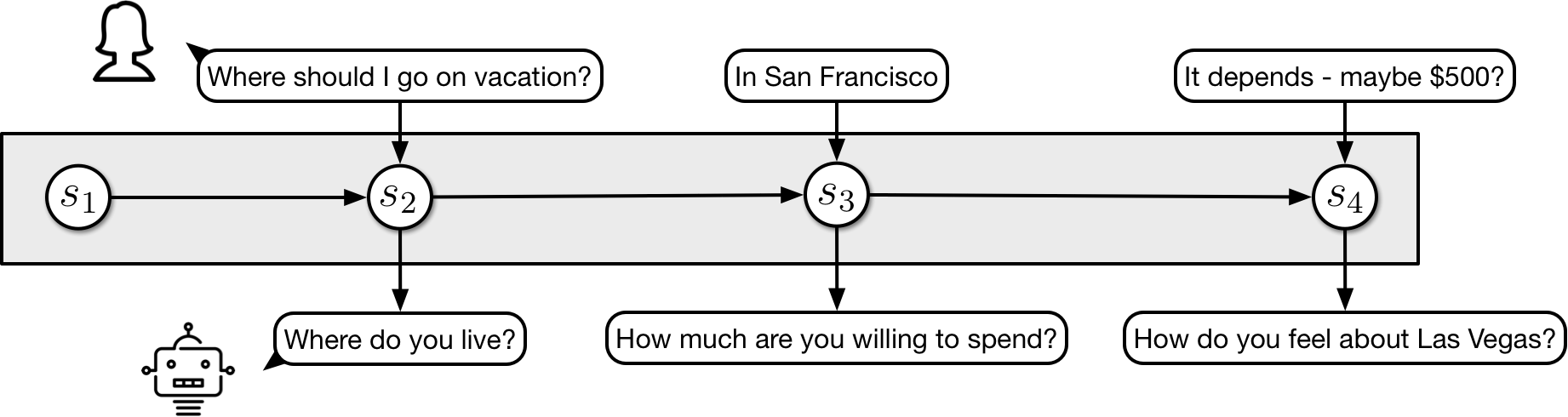
The approaches differ in how they represent this state, how they update it, and to what extent representations and update mechanisms are learned. I think it’s worth looking at a few of the more ML-based approaches to get a sense for the state of the art, so that we can then think about the challenges they face and how to address them. If you already know the field or if you’re only interested in the high-level gist, skip to Zooming out.
Reinforcement learning using POMDPs
First, we can model the conversation as a Partially Observable Markov Decision Process. As system designers, setting up a POMDP requires us to specify a number of components, including:
- State space: We choose a number of features that make up our dialog state (say 5–25). Typically, we manually decide on the meaning of each feature. For example, a feature might be what the conversation partner’s intent is out of a set
{"book new flight", "change flight", "other"}. - (Stochastic) observation function: The state is never directly observed. Instead, we maintain a belief distribution on the state, treat everything the conversation partner says as a noisy observation, and update the distribution using Bayes’ rule. This requires that we specify a distribution on utterances for each possible dialog state.
- (Stochastic) transition function: This reflects how we expect the state to change over time. For example, we may have prior beliefs about how likely it is for the partner’s intent to change at different points in the dialog.
- Action space: Our system’s actions are choices about what to say next, and here too we usually have to restrict ourselves to a fairly small pre-specified set of possible utterances.
- Reward function: At the end of the dialog (and possibly also at other times), we need a mechanism for obtaining a reward that reflects how the dialog went (e.g., whether we solved the user’s problem).
Once these elements are in place, we can learn a good policy—that is, what to say for any given belief state—using off-the-shelf RL algorithms by running the current policy on real or simulated users.
Supervised learning using neural nets
Second, the internal state can be an opaque vector of numbers, and we can learn how to update it using neural nets that are trained end-to-end on a large dataset of dialogs.
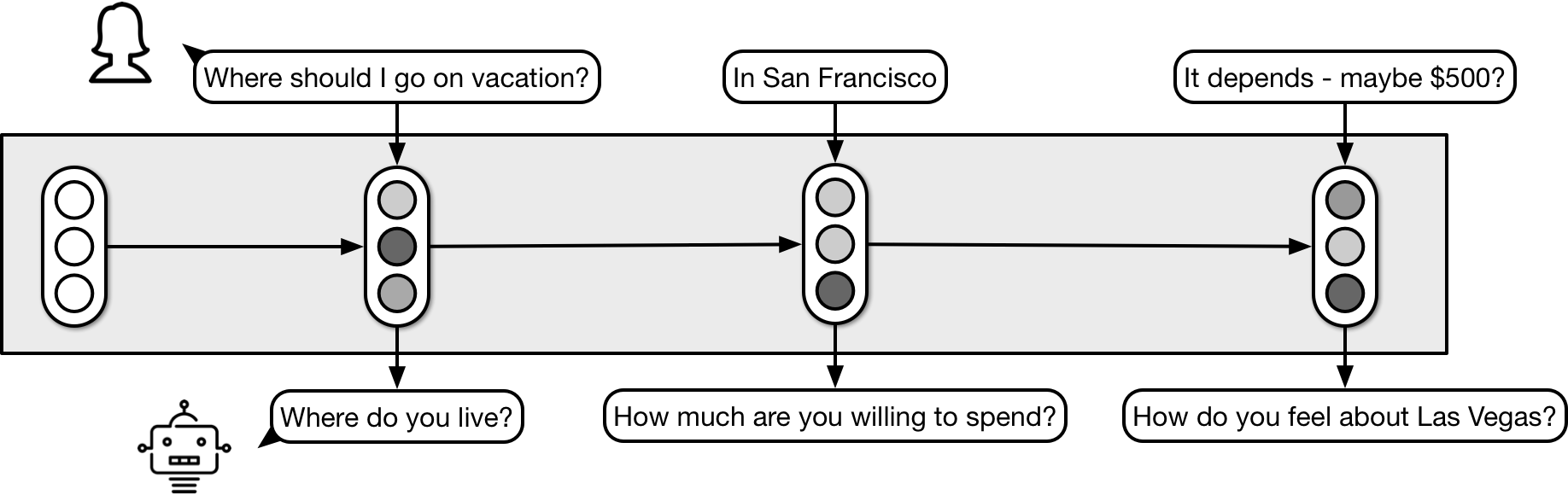
This is applicable in much more open-ended settings than the POMDP-based approach, which poses its own difficulties. The system now needs to learn to understand and use language, and to reason about the inferred content, from scratch, only given a fixed dataset of 1000–1M dialogs. This can be ameliorated to some extent by pretraining on other data and by making additional information available at runtime (e.g., via memory networks), but it’s still an extremely difficult task.
Deep reinforcement learning
Recently, researchers have started to integrate systems that are trained on large corpora with reinforcement learning. The idea is to follow an AlphaGo-like strategy: First, initialize a neural net using supervised learning based on static dialogs. Then, define a reward function that encourages certain kinds of dialogs (such as dialogs that are semantically coherent, but with fresh information added at each step) and use the Policy Gradient algorithm to optimize the neural net parameters with respect to the reward function based on conversations with itself or with real users.
Zooming out
With some loss of precision, we can view the learning problem in each of the cases above as that of learning a function from transcript history to next utterance:
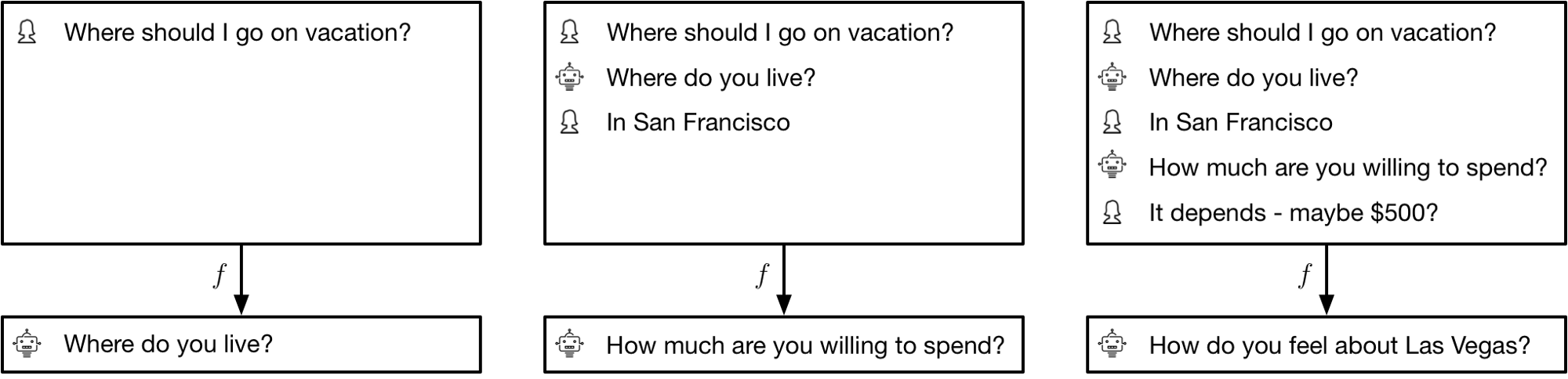
To simplify the learning problem, the approaches make (different) structural assumptions about this function. This makes the problem solvable in some simple cases, such as the restaurant booking conversations that are part of Facebook’s bAbI dialog dataset.
The approaches also optimize different objectives and use slightly different data (RL-based approaches additionally provide a reward signal at the end of each dialog) and learning strategies (RL allows for active exploration). However, they all have in common that the goal is to learn a function from transcript to next utterance.
Challenges for existing approaches
As soon as dialogs require reasoning about nontrivial domains, the learning problem quickly becomes intractable, even with a few structural assumptions about the learned function in place. This is not surprising—having human-like dialogs is the prototypical test for human-level intelligence, after all.
Still—why exactly do we run into problems if we try to apply the techniques above to such “analytic dialogs”?
We only provide remote supervision
If a system is learning directly from dialogs, the data we train on is essentially of the form (transcript, next_sentence). Note how indirect this supervision is relative to the complexity of the function that we are trying to learn.
This difficulty is especially severe for analytic dialogs, where, between one sentence and the next, we might want our system to weigh the evidence for and against different considerations, maybe query an external database, perform a calculation, or look up a definition on the Internet. Unless the domain is extremely limited, it’s difficult to see how this could be learned from static (transcript, next_sentence) pairs. The situation is a little better in the RL setting, where the system can actively seek out situations that are most informative, but the supervision is still quite remote.
Our systems have limited ability and are not aware of it
Dialog systems generally don’t know whether a predicted response is good or not, so they don’t have a principled way of choosing a null action in cases where a response is most likely inappropriate.
Unless we resort to very conservative information-retrieval methods that only provide an answer if a transcript has been seen in exactly the same form before (in which case almost all responses will be null responses), we generally have to deal with systems that can propose a response, but can’t make a well-calibrated prediction about how appropriate the response is.
For similar reasons, dialog systems generally can’t make principled decisions about when to punt to a human or other system. This makes it difficult to automatically delegate even a small part of the responses in analytic dialogs to such systems.
Our systems cannot naturally integrate human support
If we accept that current dialog systems based on machine learning are quite limited, and can hence only be a small part of a bigger system for supporting analytical reasoning, then how exactly we integrate human support becomes a key issue. In many current systems, this is at best an after-thought, but in fact, at this point, it may be more important to optimize systems for use by human contributors than for machines.
These obstacles are linked. If a system isn’t aware of its shortcomings, it cannot make smart decisions about when to abstain from taking action and get help from humans or other systems instead. If there is no natural way for humans to step in and provide fine-grained help, remote supervision based on dialog data is the best we can do.
Automating dialogs by learning cognitive actions on a shared workspace
I’ve been thinking about the challenges above and want to propose DALCA (Dialog Automation by Learning Cognitive Actions), an approach to (semi-)automated analytic dialogs that addresses the problems of remote supervision and difficult integration of human advice.
The lack of self-awareness of our systems—algorithms don’t know when their capabilities are insufficient, and so can’t decide when to abstain—is also critical, but it is somewhat orthogonal to this particular application, so I am going to mostly bracket it here. (For some work on this topic, see Li 2008, Khani 2016, and Kuleshov 2017.)
Many of the ideas below are based on the Dialog Markets tech report, but the machine learning perspective is new.
Intuition: keeping notes to organize thoughts
Suppose you are having a conversation in a setting where you are trying to help someone and it is on you to do most of the thinking. For example, as a doctor you might need to figure out what disease a new patient has and what course of treatment to prescribe. Or, as a lawyer, you are trying to come up with a plan of action for a person seeking legal advice.
In such settings, a really useful thing you can do is to write down notes to keep track of key pieces of information and to organize your thoughts about how to help. If you are not an expert—not a doctor or lawyer, in this case—your notes will likely be haphazard, and you won’t quite know how to organize them. But over time, as you are having more such dialogs with different people on similar topics, you might figure out better ways to structure information; better templates and checklists, for example.
For a dialog that starts with Bob asking “How can I find a girlfriend?”, the workspace might look like this after 20–30 exchanges:

Approach: learning cognitive actions on a shared workspace
DALCA is an approach to dialog automation that revolves around a workspace that the ML system operates on and that is shared with human contributors who can access and modify it as well. In the following, I’ll think about it as a tree-structured outline, but other choices are possible.
Given a workspace, the system’s task is to choose the next (cognitive) action. Initially, the workspace is empty. Actions typically consist of changes to the workspace (adding text, making edits, moving or deleting nodes) or a special action WAIT that causes the system to pause until the workspace changes. Other types of actions are possible as well.
Written as an algorithm, with f being a ML-based predictor:
initialize empty workspace
loop:
action = f(workspace)
if action is WAIT:
pause until workspace changes
else:
apply action to workspace
If the system is in a conversation with Alice, then adding a note “@alice What is your name?” to the workspace will send the corresponding message to Alice. If Alice replies, her response will be added as a child node to the question.
Most operations on the workspace won’t be visible to Alice, though, and only serve the system by structuring and decomposing the thoughts behind the conversation (hence “cognitive actions”).
A dialog on where to go on vacation might start like this:
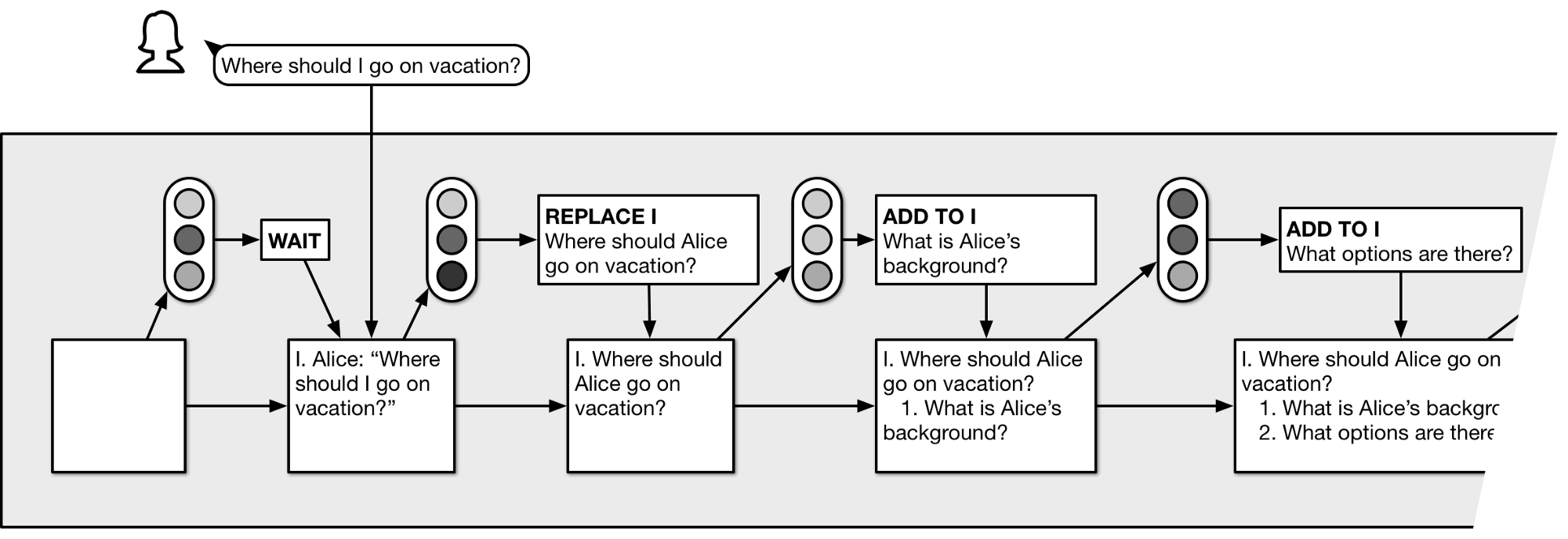
Over time, the operation of the system might look like this (click to zoom in):
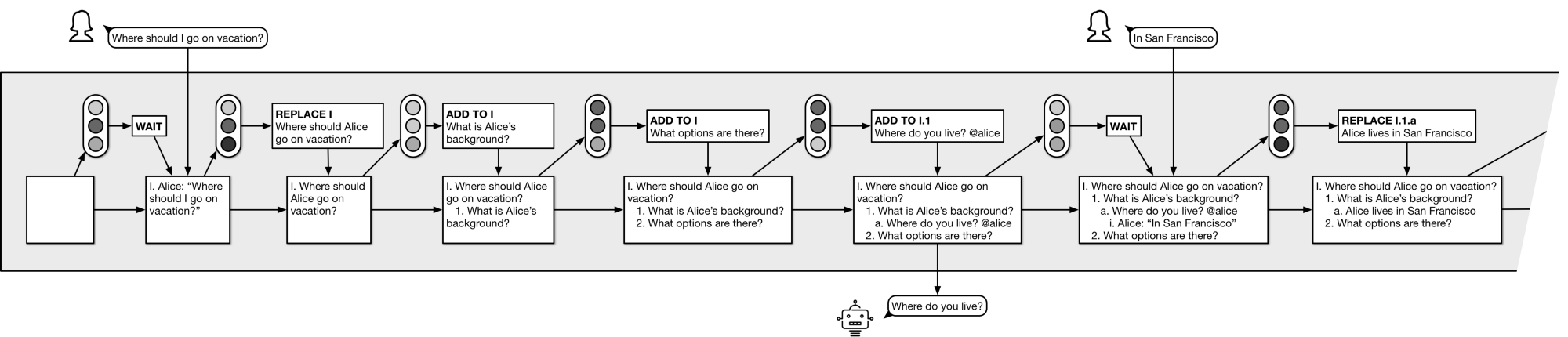
The key idea behind DALCA is that we don’t try to directly predict the next message given the transcript so far; instead, we learn to predict helpful intermediate cognitive actions.
Integration with human support and other systems
The presence of a transparent workspace that is the basis for choosing a next action makes it easy to integrate other systems. At any time, a human contributor can make changes to the state if they think it would be advantageous. If the system decides that it needs help, it can post a question to the workspace and wait for a response.
This doesn’t just apply to human help. Doing calculations or looking up information in a database are tasks that our machine learning system probably shouldn’t implement directly, but rather (learn how to) delegate to domain-specific tools. Similarly, looking up the user’s IP address and retrieving a location for the IP can easily be outsourced to domain-specific bots (again, click to zoom in):

By decomposing cognitive tasks into parts that current machine learning systems can do, parts that other specialized tools can handle, and parts that only humans can accomplish, we can try to delegate as much of the work as possible to machines. Over time, I expect this fraction to grow.
Learning cognitive actions from data
The learning problem now is to learn a function workspace -> next_action where next_action will contain the operation type (add, move, edit, delete, wait) and necessary data, such as the identity of a node we are operating on or the text we are adding. We can treat this as a supervised learning problem based on data of the form (workspace, next_action).
While I expect this learning problem to be somewhat easier than the task of directly learning transcript -> next_sentence, it is still very challenging, and it has the disadvantage that we don’t have existing training data, while we do have existing dialogs. In other articles, I’ll talk about how to gather such training data. (Preview: We’ll set up a market that incentivizes helpful workspace actions from a crowd of human contributors.)
There are also a few other differences to the standard dialog automation learning problem, such as the fact that our contexts are now trees (the workspace), not sequences (the transcript), and that our outputs are now generalized actions, not just utterances.
There is a lot of room for applying existing ideas to this new setting. To give three examples:
- We could explore semi-supervised learning based on existing dialogs, with only a few dialogs annotated with workspaces.
- We could use attention models to incrementally predict actions by first choosing what nodes to focus on, then what change to make to those nodes.
- We could initialize our model using supervised learning on workspace-annotated dialog data collected from humans and then fine-tune it using reinforcement learning. (Purely supervised learning can lead to short-sighted actions, as described in Li 2016, and RL is probably necessary to get to superhuman performance.)
Choosing if and when to act
The standard approach to dialog automation is synchronous. The user sends a message, the system responds, the user replies, etc. The system doesn’t need to decide when and whether to act—whenever the user sends a message, it has to return a response.
Under DALCA, the system’s operation is more asynchronous. The system doesn’t need to wait for a message from the user; instead, it can take actions that modify the workspace at any time.
This also means that, at each point, the system needs to decide whether it has sufficient capability to take a good action or whether it is better to wait until someone else makes a change to the workspace (e.g., the user, human helpers, or other systems). As a consequence, the choice whether to act is a fundamental part of the system’s operation, and the decision not to send a response to the user is simply a special case of the decision not to take any action on the workspace.
End-to-end dialog automation as a special case
If we only append messages to and from the dialog partner to the workspace, without any additional intermediate steps that are hidden from the user, we recover the standard approach to dialog automation.
Relation to memory-augmented neural nets
In the last few years, researchers have started using neural nets that learn to read from and write to external memory structures (e.g., Weston 2015, Sukhbaatar 2015, Graves 2016). In a few instances, these have been applied to dialog modeling (e.g., Perez 2016). DALCA similarly augments neural nets with an external memory structure, but this structure is expressed in natural language and is readable and writable by human contributors.
Conclusion
The learning problem for dialog automation remains very challenging, even if we learn small-step cognitive actions on a human-readable workspace. However, it is now easier for people to step in and provide fine-grained help. Indeed, I suspect that having multiple people collaboratively edit the workspace could result in helpful dialogs even if there is no machine learning involved at all. If this is the case, we can gracefully scale the system over time from fully crowdsourced to fully automated.