Elicit
Elicit is an AI assistant for researchers and academics, incubated at Ought and now running as an independent public benefit corporation.
The plan for Elicit
Our goal is to automate and scale open-ended reasoning with language models—synthesizing evidence and arguments, designing research plans, and evaluating interventions.
We started with automating literature reviews because:
- There is a rich discipline around synthesizing literature.
- Understanding the status quo is necessary to expand the frontier.
- Researchers most want help with literature review.
Today, Elicit users find academic papers, ask questions about them, and summarize their findings.
After literature review, Elicit will expand to other research tasks (evaluating project directions, decomposing research questions, augmented reading), then beyond research (supporting organizational planning, individual decision-making).
Read more about the plan for Elicit.
The case for Elicit
Robust, well-reasoned research is the bottleneck for many impactful interventions and decisions. Language models can address this bottleneck by reading and evaluating more research, evidence, and reasoning steps than humanly possible.
Like programming languages provide building blocks for exact computation, language models provide the building blocks of cognitive work (e.g., search, extraction, classification, summarization). Elicit will study researchers, identify and build out these blocks, then surface them to users so that they can string them together and automate their cognitive workflows over time.
If Elicit succeeds, this will make researchers vastly more productive and accurate. It will also help non-experts apply good research and reasoning practices when discovering, consuming, and generating information.
Elicit's architecture is based on supervising reasoning processes, not outcomes. While this architecture is being built in the context of a research assistant, we expect to learn how to make machine learning useful for open-ended questions more broadly (differential capabilities). In the long run, process-based architectures can avoid some alignment risks posed by end-to-end optimization (alignment).
- Differential capabilities: End-to-end training based on outcomes doesn't work well for exceeding human capability at questions that don't have easily measurable outcomes, questions like "Does this plan have problematic long-term consequences?". If we want AI to be as helpful for such long-horizon tasks as it is for "Did this chat interaction persuade them to click 'buy'?", we need a paradigm that isn't based on end-to-end training.
- Alignment: As AI becomes more powerful, AI systems trained end-to-end are incentivized to game their reward metrics. The compositional approach evaluates process instead of outcome, thus providing a more robust alternative.
Read more about the case for process-based architectures.
Infrastructure for Elicit
To demonstrate how to build tools like Elicit in a process-based way, we developed the Interactive Composition Explorer (ICE), an open-source Python library for compositional language model programs.
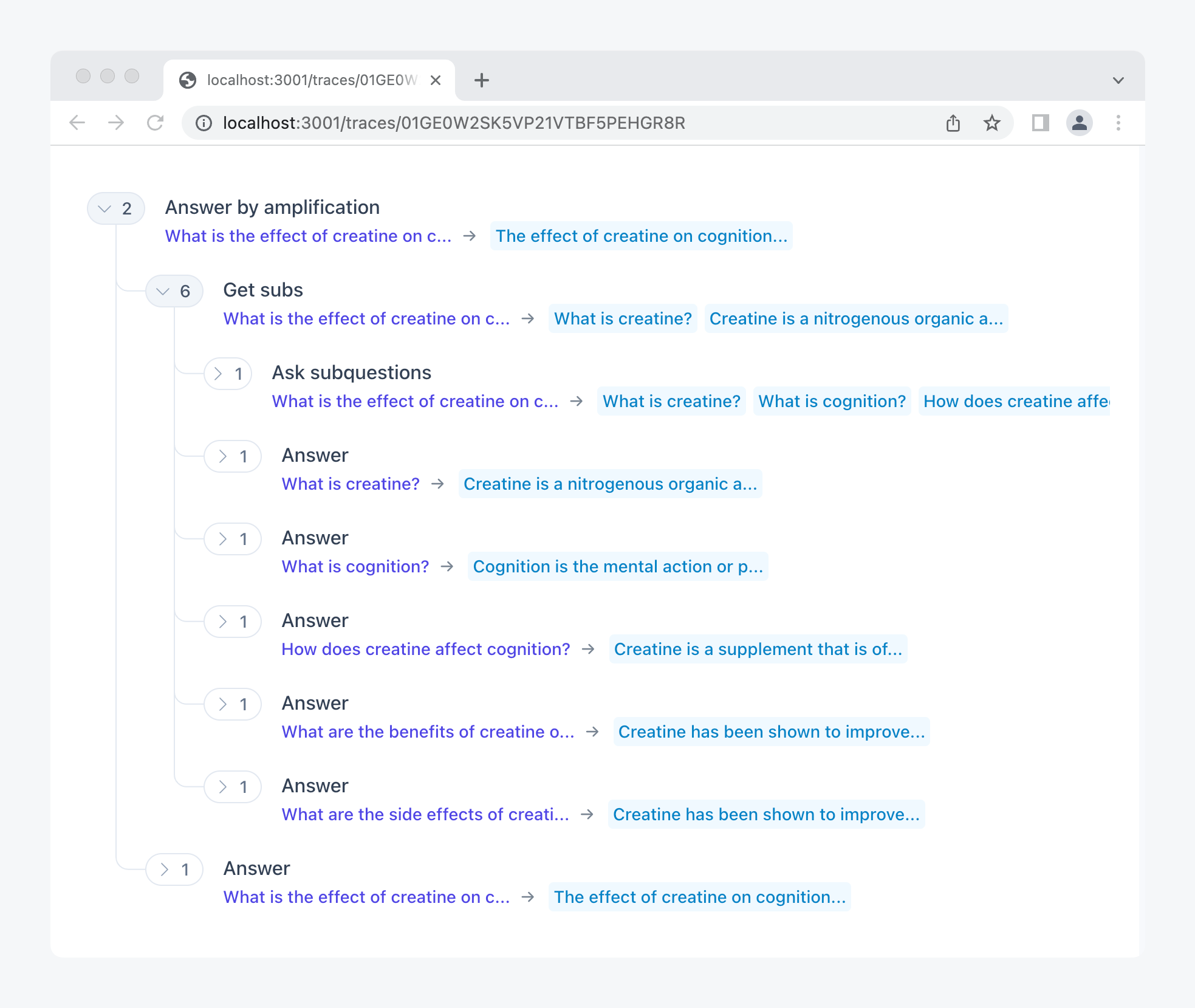
To learn how to use ICE, read the Factored Cognition Primer, an online tutorial that walks you through solving complex reasoning problems using task decomposition.