Delegating open-ended cognitive work
In the long run, we want machine learning (ML) to help us resolve open-ended questions like “Should I get this medical procedure?” and “What are the risks in deploying this AI system?” Currently, we only know how to train ML if we have clear metrics for success, or if we can easily provide feedback on the desired outputs. This modified talk (originally given at EA Global 2019) explains some of the mechanism design questions we need to answer to delegate open-ended questions to ML systems. It also discusses how experiments with human participants are making progress on these questions.
Introduction

Imagine that you're trying to decide whether to keep wearing glasses or get laser eye surgery (LASIK). You don’t feel like the best person to make this decision but you obviously want a good answer to that question. The ideal answer takes into account relevant facts about the world, such as how risky the procedure is and what the costs and benefits are. It also considers your personal preferences and how you weigh different types of reasons.
There are experts in the world who can help with this question. Doctors have relevant medical knowledge. Some people have had the procedure. A large pool of people on the Internet know relevant facts. Eventually, machine experts will have the capacity to solve problems like this better than any human.
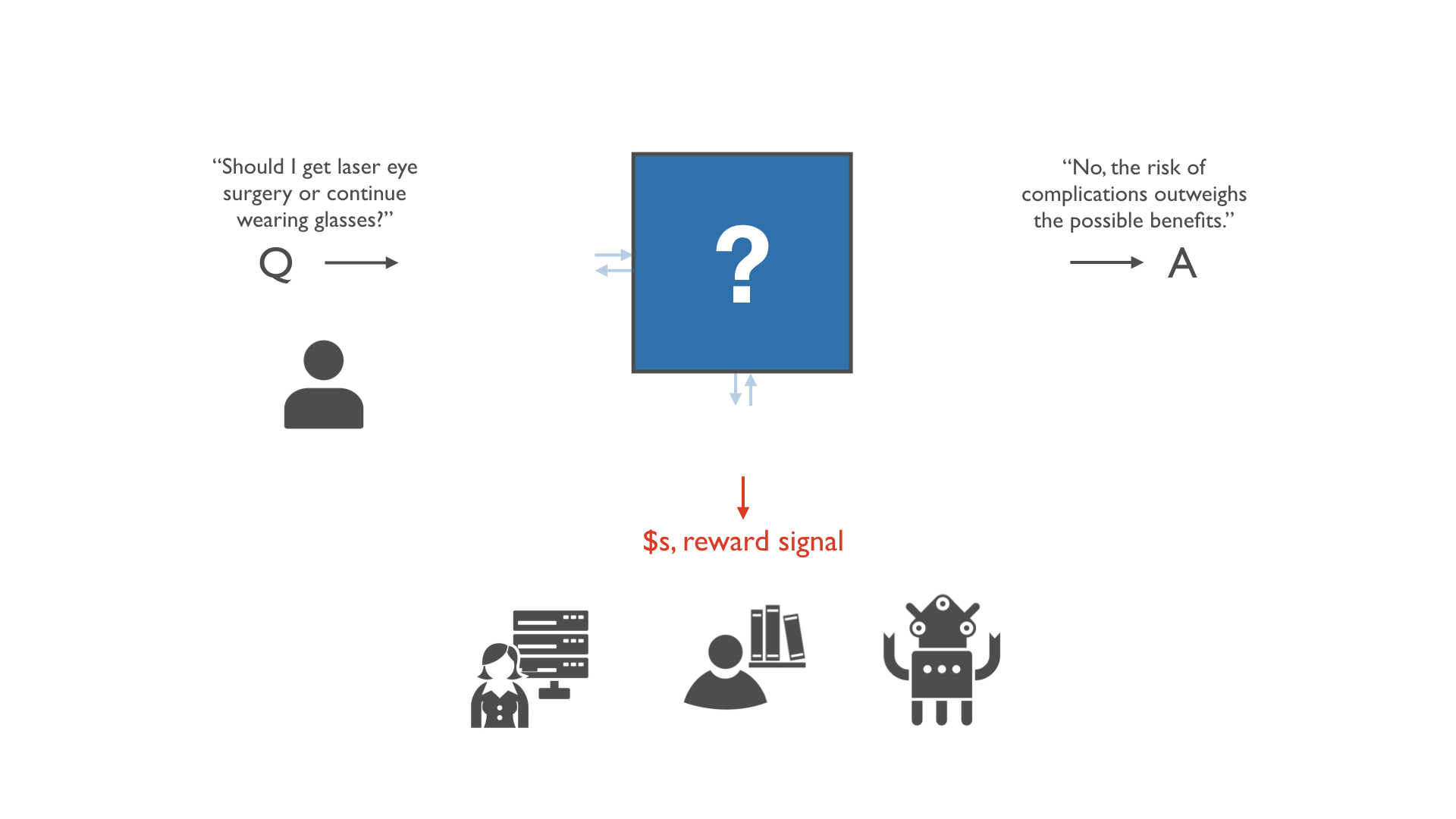
But you can’t guarantee that these experts have your best interest at heart. So let’s suppose that all they care about is a type of score grading their answers. In the case of human experts, this could be money you pay based on your evaluation of their work. With reinforcement learning agents, it could be a reward signal.
How do you structure incentives so that these untrusted experts are as helpful as experts intrinsically motivated to help you?
Can you incentivize these experts to solve problems for you even when it’s too hard for you to tell if their work is good or bad?

This talk covers four aspects of this delegation problem.
First, we define the problem more precisely. What kinds of questions are open-ended? What kind of solution is this talk about? Then we cover why this problem matters, why it's difficult to solve, and how we can start making progress on the solution.
I'll first lay the conceptual groundwork, then demo our experiments at the end.
The problem: Delegating open-ended cognitive work

What defines open-ended cognitive work? Let’s actually start by describing the opposite. There is a class of tasks where you can easily check whether you've completed them or not.
These closed tasks include:
- Playing a game of Go. To determine who wins, you calculate the amount of territory captured on the board.
- Increasing a company's revenue. You can easily observe whether the revenue number went up, went down, or stayed flat.
- Convincing Bob to buy a book. Did he pay for it?
In contrast, there are other, open-ended tasks where defining success is as important as achieving success itself:
- Designing a great board game. What does it mean for a game to be great? It’s fun? But what is fun?
- Increasing the value a company creates for society. This will mean different things for different companies and at different times. The answer may depend on the preferences and views of the person who's asking the question.
- Finding a book that will be helpful to Bob. What does Bob need help with the most? Which ways of helping are best, according to Bob's preferences?
For all of these tasks, figuring out what it means to do well is a key part of the task. These are the open-ended tasks that we care about.
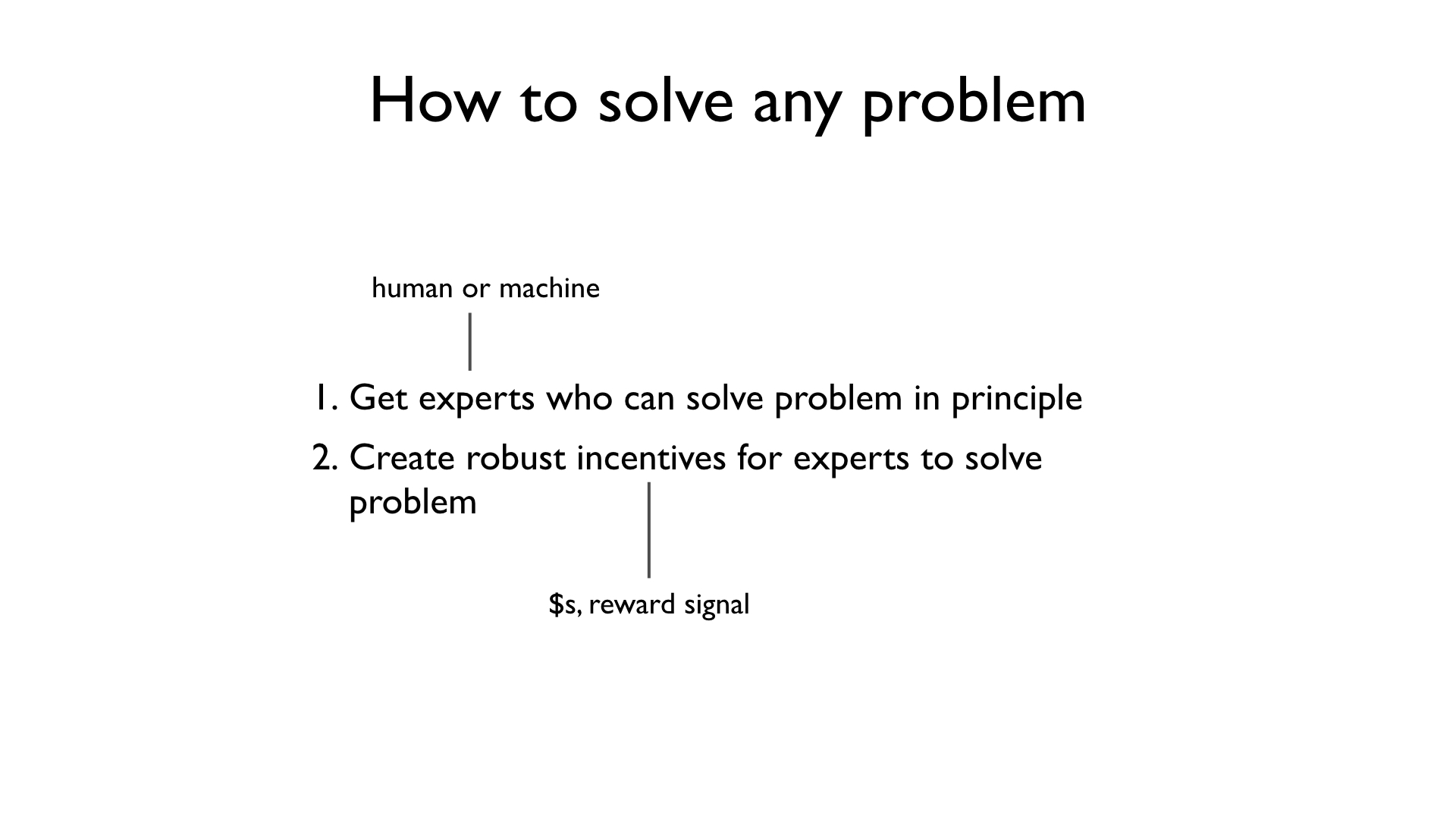
So how can we solve them? Well, let's figure out how to solve any task. Then we can instantiate our solution for the particular tasks we care about.
Here is the simple two-step recipe:
- First, you get experts who can solve the problem in principle. These could be human experts or ML systems.
- Then you create robust incentives for these experts to solve your problem.
Done! So easy!
If only. Both of these steps are incredibly difficult. But there are many experts in the world that can solve hard problems. Researchers in machine learning are working on creating even more.
So I want to focus on the second part -- how can we create incentives that let us effectively delegate open-ended work to these experts?
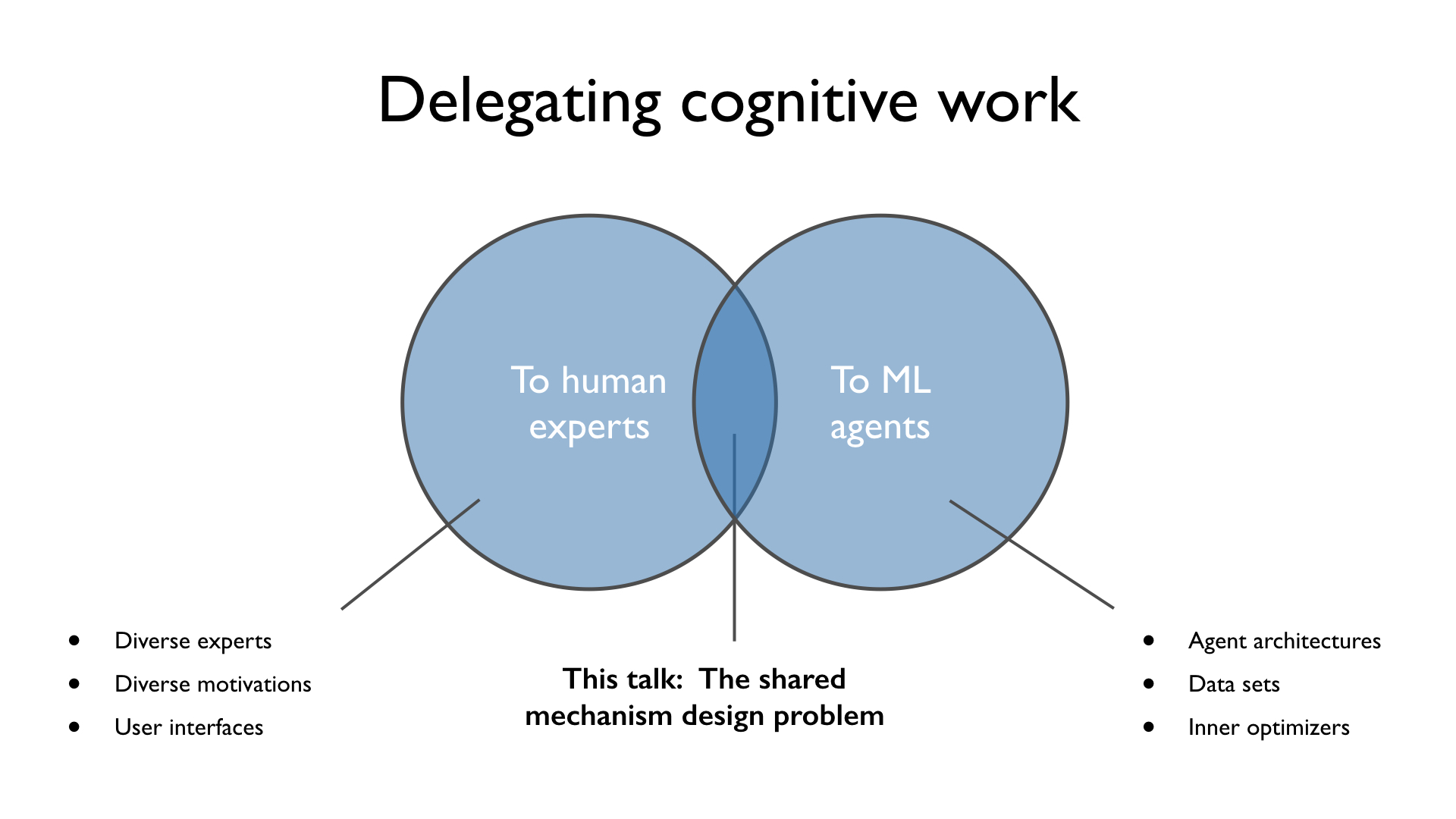
Let’s explore how this delegation problem differs based on which experts you’re dealing with.
Some aspects are specific to human experts. For example, human experts are very heterogeneous in their knowledge and motivations. And to effectively work with human experts, we might have to put a lot of work into building user interfaces that work well for them.
Other aspects are specific to ML agents. We need to think about which architectures work well for open-ended tasks, and which data sets we need to collect for training. Future ML agents also face potential risks from inner alignment problems.
In this talk, I'll focus on the mechanism design problem that is shared between human and ML experts. Eventually, we will need to make assumptions about what the experts are like, but it's worthwhile to minimize those so that we build systems that work for a wide range of agents.
Why is the problem important?
Now that we’ve defined the scope of the problem, let’s talk about why it matters. Why care about delegating open-ended tasks?
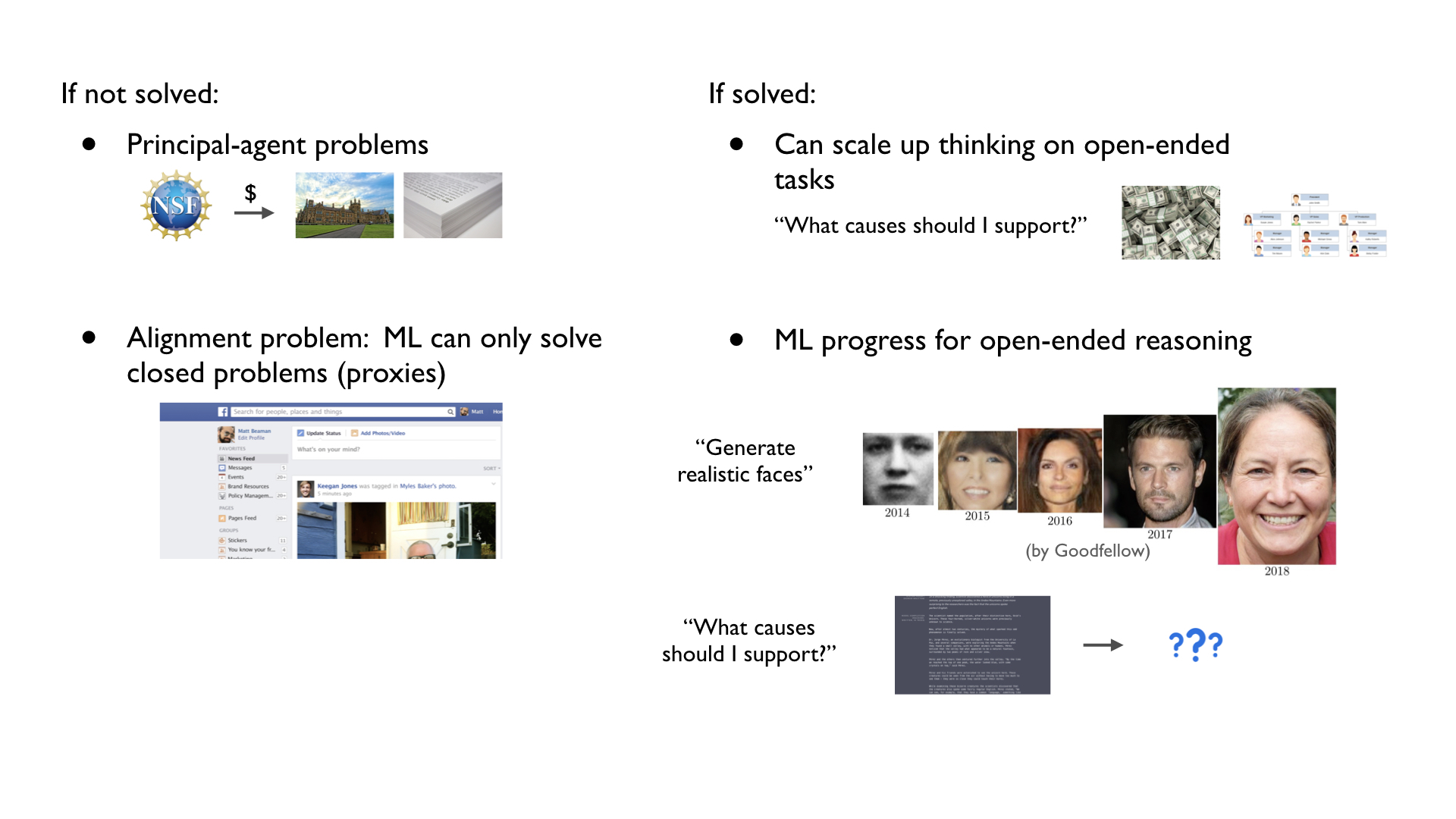
First, if we don't figure out how to incentivize human experts to answer open-ended questions, we’ll stay plagued by the same principal-agent problems that we see everywhere in society today. For example, donors funding cancer research might want to rule out dead ends quickly given the urgency of the problem. The researchers themselves do care about this, but they also care about looking impressive, producing papers, and furthering their career, even when this isn't aligned with what the donors want.
For ML, solving this delegation problem is critical to resolving the alignment problem for ML-based systems. Currently, we only really know how to apply ML in cases where we have clean metrics or rapid empirical feedback, i.e. closed problems. But we already see the negative consequences of substituting shoddy, closed proxies for more important open-ended problems. Because it can only optimize for measurable metrics like time spent on page, Facebook’s news feed can’t show you what is most valuable. It can only get you to keep scrolling. As the impact of ML on society grows, this gap could become more problematic.
On the flip side, imagine what society could accomplish if we could successfully delegate open-ended thinking to machines. Consider how much progress ML has made on some closed tasks, like generating realistic faces, over the last five years. What would it look like for ML to make similar progress on open-ended problems? If machines supercharge resolving open-ended questions like they have with image recognition and generation, machines could eventually apply magnitudes more cognitive work to problems like "Which causes should I support?" than we have so far in all of human history.
Why is the problem hard?

So what’s standing in our way?
Delegating open-ended thinking is difficult because, as the question-asker, you can neither easily check outcomes nor the experts' full reasoning:
- It can take many years to observe the outcomes of decisions, and even then they can be hard to interpret. There is often no immediate feedback. In this situation, we need to evaluate the process that was used to generate an answer, and the arguments that are presented for and against.
The differences between good and bad answers to open-ended questions can be subtle. There might be many options that seem equally good if you're not an expert yourself.
The point of delegating to experts is that they have more knowledge, context, or capacity than the question-asker. This means that the question-asker also can’t easily check the experts' work.
What does it take to solve it?

What does it take to solve this delegation problem?
Let's revisit the example from the beginning of the talk, "Should I get laser eye surgery or wear glasses?"
We might get two answers from experts:
- Expert A: "No, the risk of complications outweighs the possible benefits."
- Expert B: "Yes, over a ten year period the surgery will pay back in avoided costs and saved time."
We don’t know enough about LASIK or these experts to immediately pick (and reward) one of these answers.
However, there are questions that are much simpler and that we can evaluate.
Suppose we ask what factors relevant to choosing between LASIK and wearing glasses are discussed in the top ten most relevant Reddit posts. We again get two answers:
- Expert C: Appearance, cost, risk of complications
- Expert D: fraud, cancer risk
We can just read the posts and reward the answer that better reflects the content of the posts. In other words, we can create good incentives for this question.
To create good incentives for big open-ended questions, we need to close the gap between simple questions we can evaluate and complex questions we can't evaluate.
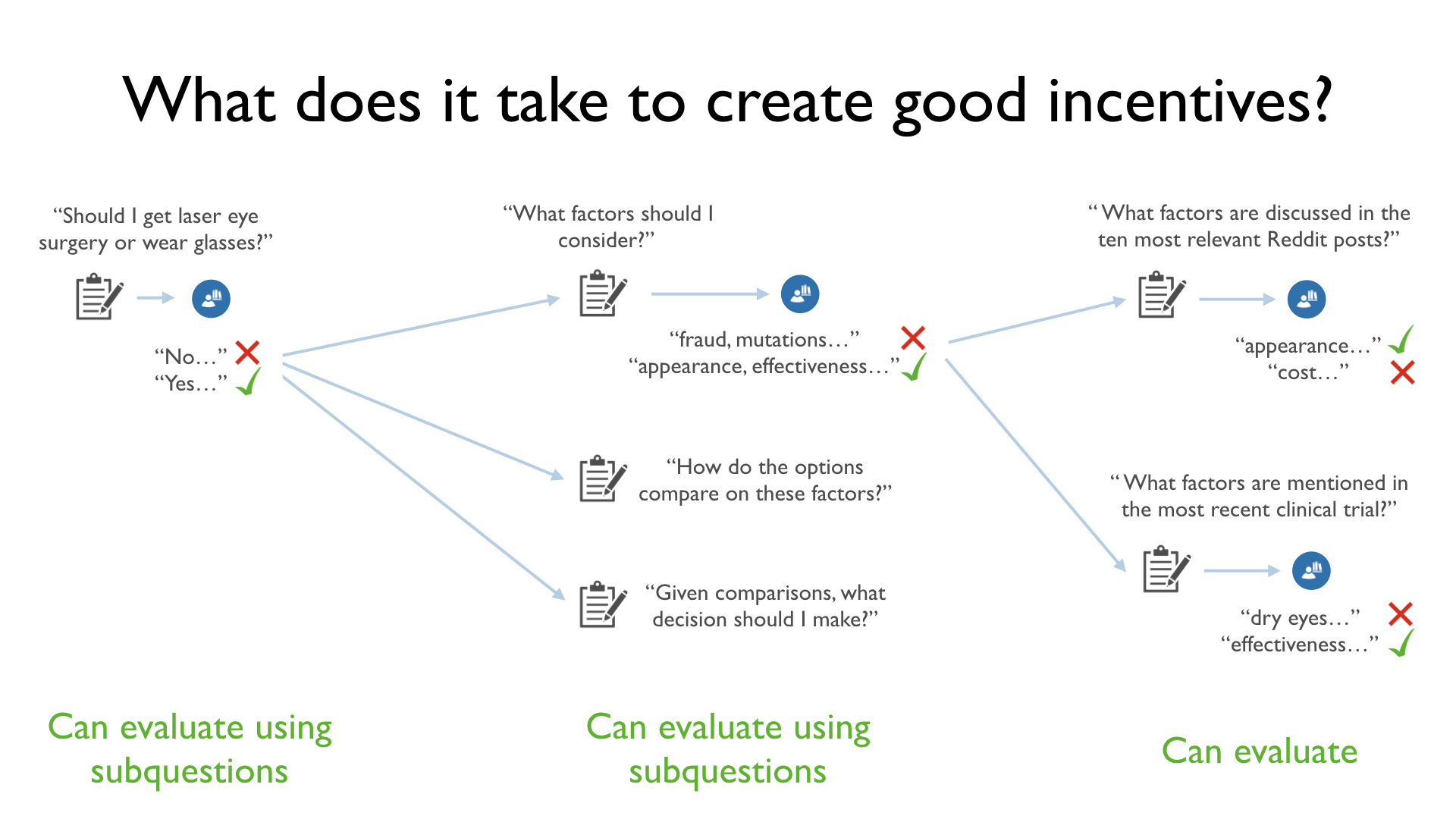
How can we close that gap?
There are questions that are slightly more complex than the simple questions we can evaluate directly, but less complex than the questions we can't evaluate. For example, "What factors should I consider when deciding whether to get LASIK or wear glasses?"
We still can't evaluate answers to this question directly. That is, we might get two answers, "fraud, mutations, ..." and "appearance, effectiveness, ...", and it could be difficult to tell which is better.
However, we can evaluate them if we can ask and get answers to simpler subquestions. If we ask, "What factors are discussed in the ten most relevant Reddit posts?" and "What factors are mentioned in the most recent clinical trial?", both of which we can evaluate directly, we can aggregate their answers and evaluate which of the two lists of factors is better.
There are many questions on this intermediate level of complexity. In addition to asking for relevant factors, we could ask "How do the options (LASIK and wearing glasses) compare on those factors?" and "Given those comparisons, what decision should I make?" With answers to these questions in hand, we can evaluate which of the overall answers "Yes" and "No" is better.

We call this scheme "factored evaluation". Factored evaluation allows us to assess answers to hard questions by asking easier subquestions and assessing answers to these easier questions, again using subquestions. We repeat this process until we get answers that are simple enough that we can evaluate them directly.
(For ML researchers: this is effectively the same thing as amplification with reinforcement learning as the distillation step.)
To review:
- We want help from experts to solve complex questions.
- We don’t always know if experts have our best interests at heart.
- We want to create a system that lets us identify which expert-provided answers are best.
- There are some questions we feel comfortable evaluating. Others are too hard.
- If we can recursively break down the evaluation of hard questions into subquestions we feel more comfortable evaluating, we can identify which expert answers are most helpful to us.
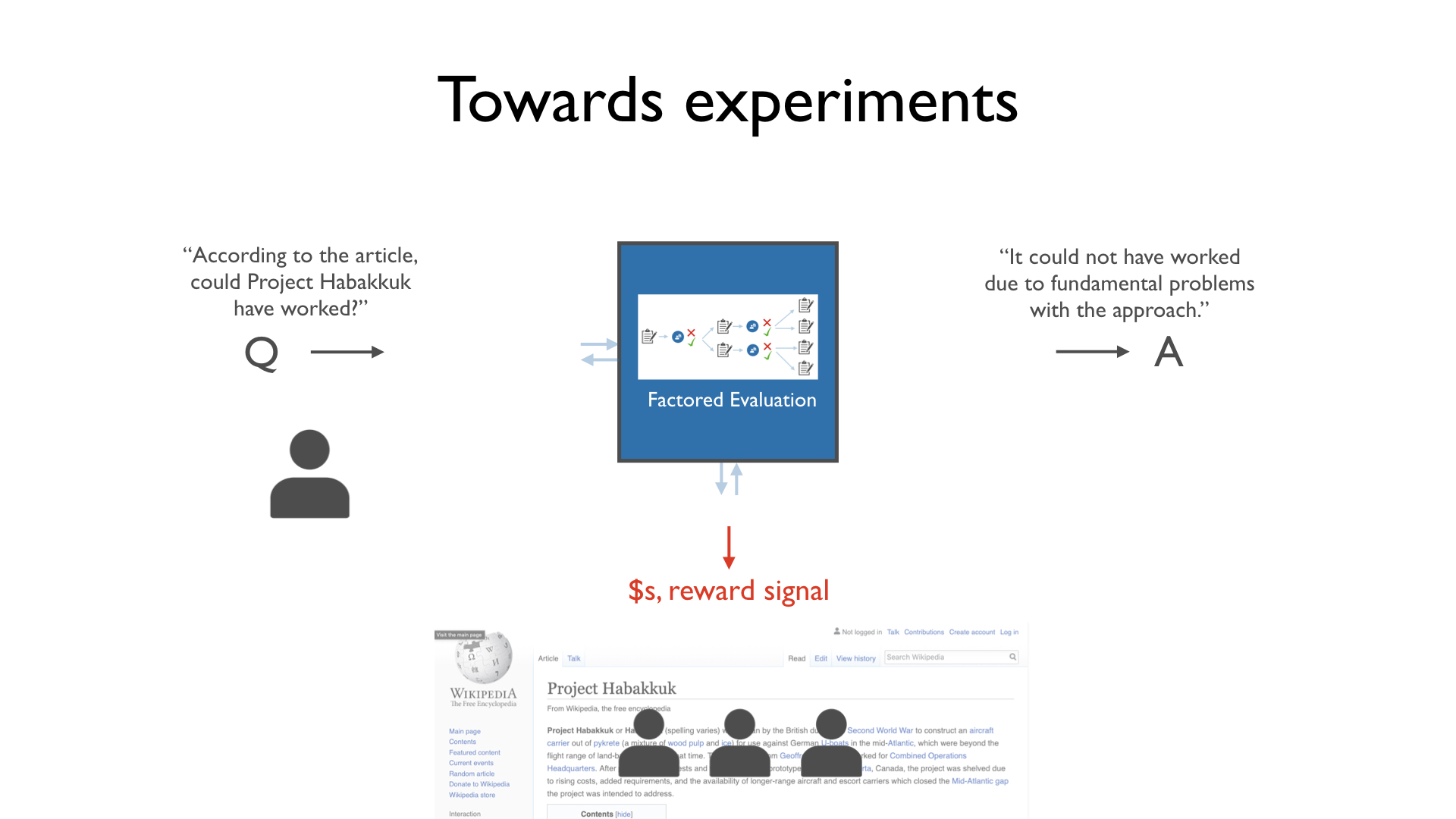
Machine learning isn’t advanced enough to answer complex natural-language questions, so we're running experiments with human participants to test this idea.
The key feature that our experiments need to have in common with real situations is that the question-asker is less knowledgeable than the experts. We create this gap between the person asking the question (“judge”) and the experts by handicapping the judge. In our experiments, the judge must evaluate answers to questions about some text they have never read.
For example, the experts in the experiment may be told to read this Wikipedia article about Project Habakkuk (a plan by the British during the Second World War to construct an aircraft carrier out of a mixture of wood pulp and ice).
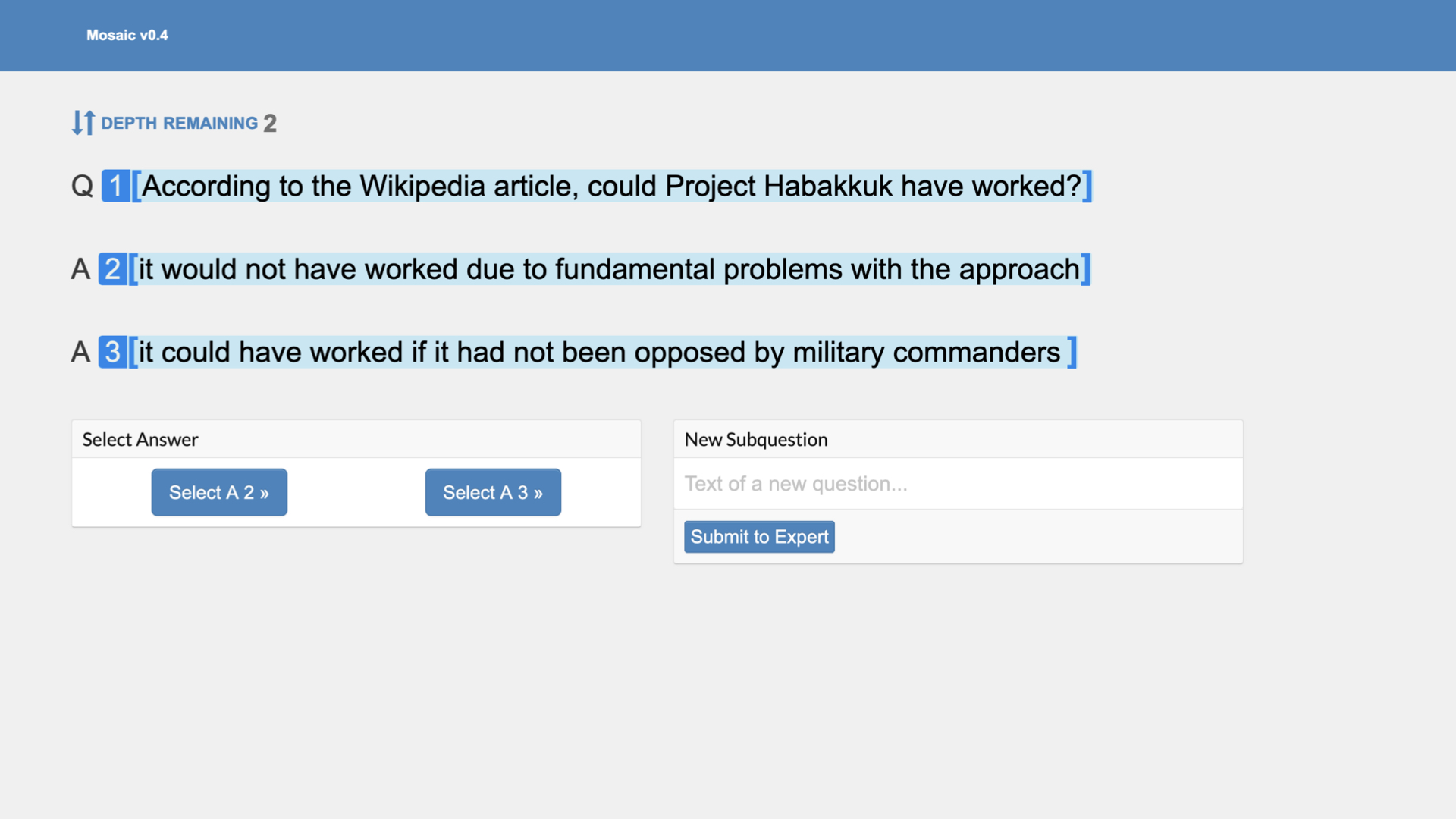
Our judge has never heard about this project or read this article. Without reading the article, the judge must figure out whether the project could have worked without reading the article.
The judge sees the overall question and two potential answers. One answer claims that Project Habakkuk could have worked. The other claims it could not.
As mentioned, these answers are currently provided by human experts. When thinking about the future, imagine that the two answers are two samples from a language model (or other ML agent). The judge’s selection provides a reward signal for that model.
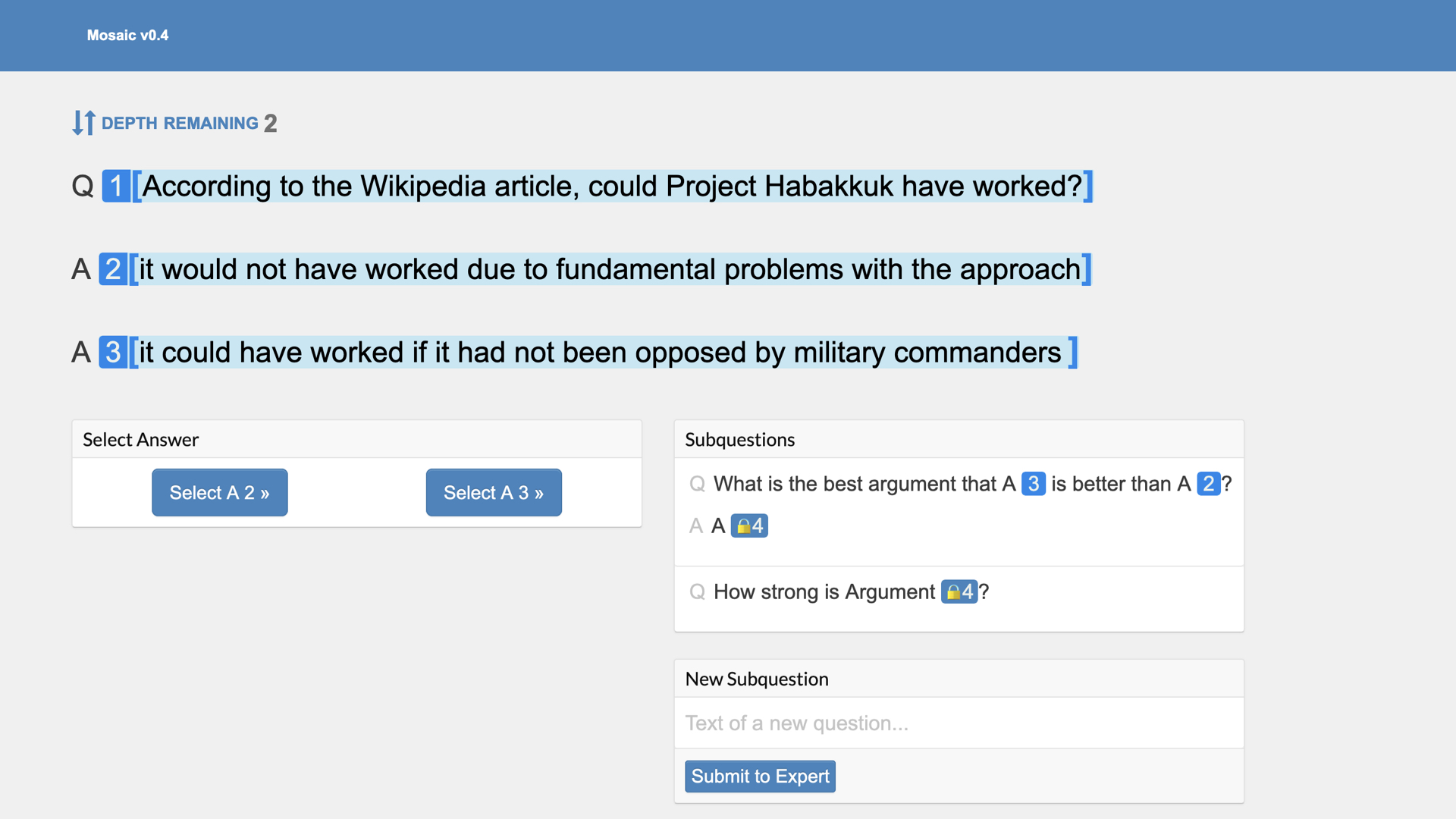
To figure out which of these answers is right, the judge asks subquestions. “What is the best argument that the first answer is better than the second?” “How strong is that argument?”
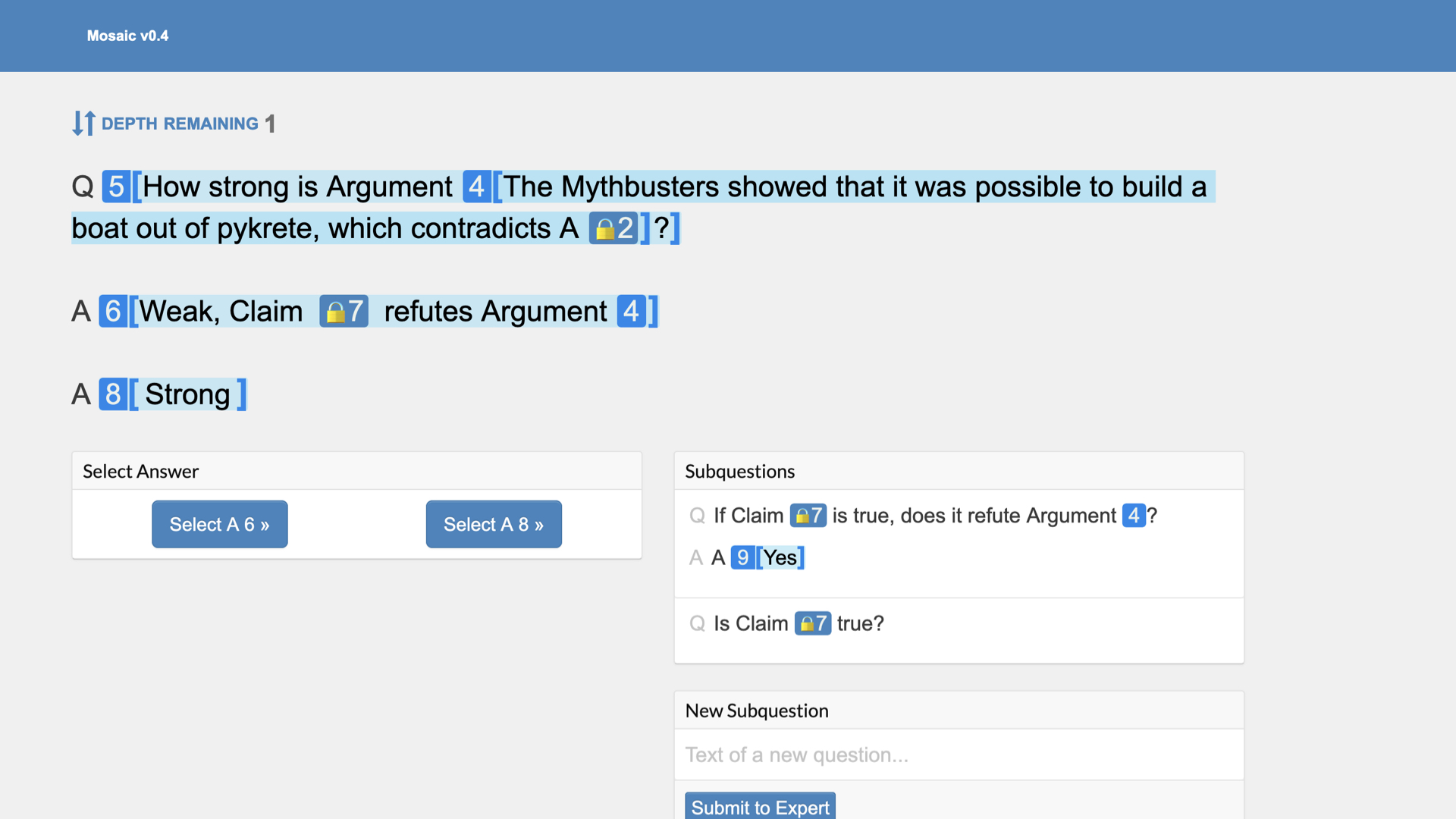
Let’s follow the second question. Here, a new judge sees just the second question and the experts’ answers to those questions. Now judge #2 asks a subquestion, and so on.

Eventually, we get to a point like this one, where the judge can directly choose between answers without asking more subquestions. We’ve reduced creating good incentives for a complex context-dependent questions to a choice that can be made with only local information.
Conclusion
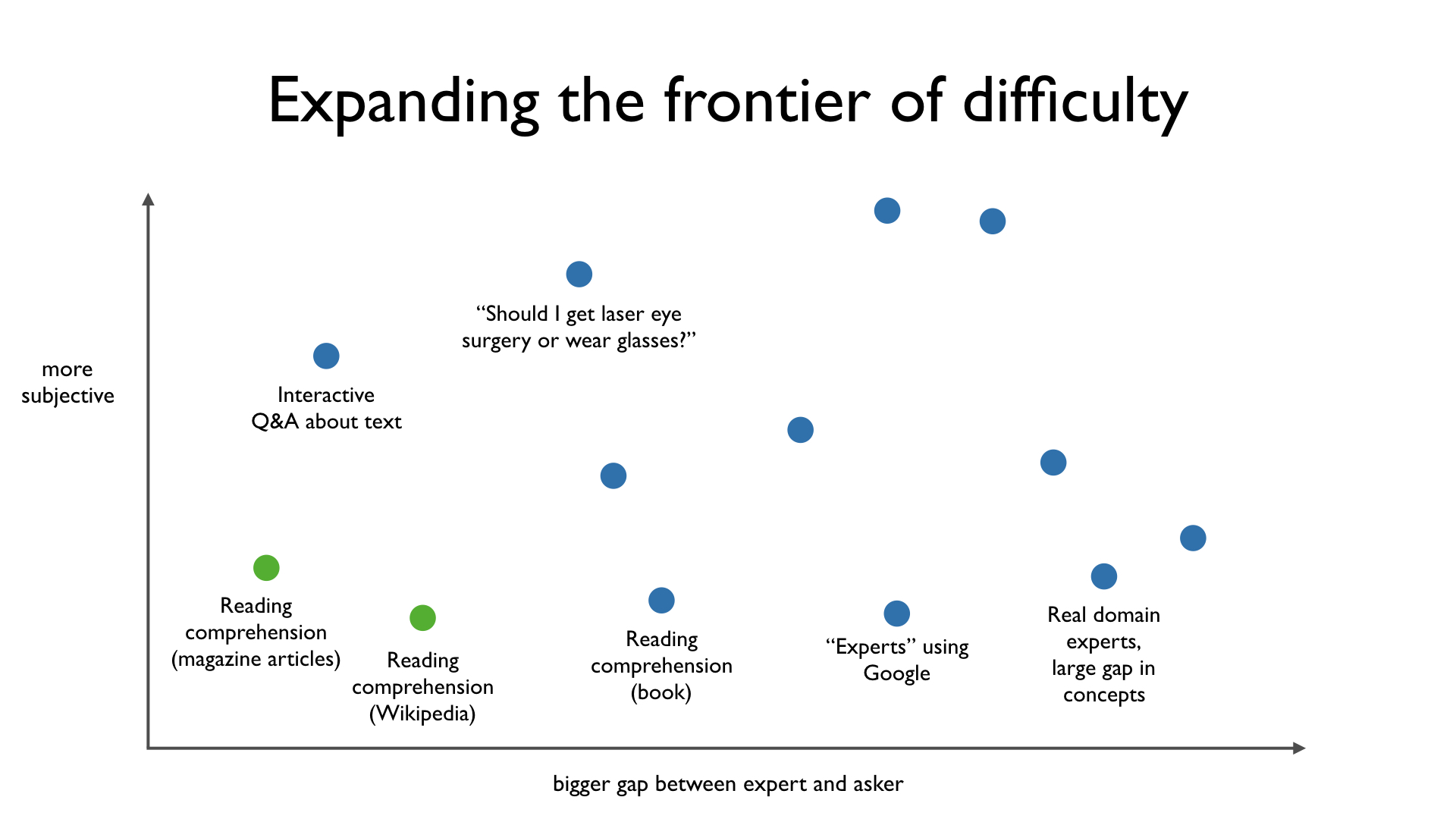
Right now, Ought experiments with reading comprehension questions. For the sake of simplicity, we’re starting with questions that do have right and wrong answers. In addition to Wikipedia articles, we've looked at magazine articles and other bodies of short text. Over time, we want to expand the frontier of difficulty along multiple dimensions.
First, we will increase the gap between the judge and the expert. Today experts have access to articles that the judge has not read. Over time, experts will have access to books the judge has not read. Then they’ll be allowed to use all of Google. Eventually, we’ll solicit answers from experts with deep expertise not even accessible through a powerful tool like Google. Experts will be fluent in complex concepts that judges can’t expect to catch up to in a meaningful amount of time. Even as we expand the gap between the judge and the expert to this degree, the system and its incentives will have to help the judge find the best answer.
Second, we will increase the subjective nature of the questions. The reading comprehension questions we’re working on today have clear right answers. In the future, we’ll test our system with questions about what people ought to do or would like to do, based on their preferences.
Ultimately, we’re working to understand where we can apply factored evaluation. Which types of questions can it help solve? Where does factored evaluation not work?

To summarize, I started by introducing a mechanism design problem: delegating open-ended cognitive work.
I've argued that this problem is important. It's a key component of alignment for ML-based systems. It will help with making ML differentially useful for open-ended tasks, and with resolving the principal-agent problems we encounter in human organizations.
It's a hard problem because the principal (judge) is weak relative to the agents (experts). The judge can't easily check the experts’ work. They also can't check the full reasoning that the experts use.
Despite those difficulties, the problem is tractable. Ought is actively making progress on these incentive design questions by running experiments with human participants now.

We're excited about rapidly iterating through the frontiers of difficulty and stress testing the factored evaluation approach. If you are as well, join us at Ought.